PostgreSQL cluster: partitioning with plproxy (part II)
In the last post i described how you can setup plproxy and create a basic horizontally partitioned cluster. Now we will take a look at another real life usage: building a read-only cluster for your database
Distributing read-only load
The simplest real world usage for plproxy would be it’s use for redirecting read-only queries to read-only replicas of master database. The replicated databases can be filled with data via Londiste that is part of the SkyTools package, setup tutorial can be found here or with Slony which is a more heavyweight solution but from my own experience also harder to setup and maintain though definitely at the time being better documented.
A typical read-only cluster could look like on the following schema. The databases with the letter (P) on them are connection poolers. We ourself use PgBouncer but pgpool is also a choice.
The poolers are needed to minimize the number of open connections to a database also execution plans are cached on a connection basis. Of course everything will work fine also without the poolers. Dashed bold arrows represent replicas.
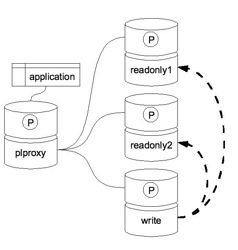
In this setup the plproxy functions determine the database to which the query is redirected. Read&write queries go to master database and read-only queries are distributed based on the algorithm you define to read-only replicas.
Setting up replication itself is relatively easy once you have passed the painful skytools installation process.
First let us create both replicas from write database toward ro1 & ro2. ro1 configuration file looks like this:
replica1.ini
[londiste] job_name = londiste_master_to_r1 provider_db = dbname=write subscriber_db = dbname=ro1 # it will be used as sql ident so no dots/spaces pgq_queue_name = londiste.write pidfile = %(job_name)s.pid logfile = %(job_name)s.log use_skylog = 0
replica2.ini is basically the same only job name and database name need to be changed. Now let’s install Londiste on provider (write) and subscribers (ro1,ro2) and start the replication daemons:
mbpro:~/temp kristokaiv$ londiste.py replica1.ini provider install mbpro:~/temp kristokaiv$ londiste.py replica1.ini subscriber install mbpro:~/temp kristokaiv$ londiste.py replica2.ini subscriber install mbpro:~/temp kristokaiv$ londiste.py replica1.ini replay -d mbpro:~/temp kristokaiv$ londiste.py replica2.ini replay -d
The next thing you need to do is to setup the ticker process on the database where write is performed. The ticker creates sync events so running it with shorter intervals will reduce latency. My configuration file looks like this:
ticker_write.ini
[pgqadm] job_name = ticker_write db = dbname=write # how often to run maintenance [minutes] maint_delay_min = 1 # how often to check for activity [secs] loop_delay = 0.1 logfile = %(job_name)s.log pidfile = %(job_name)s.pid use_skylog = 0
To start the ticker as a daemon just run:
mbpro:~/temp kristokaiv$ pgqadm.py ticker_write.ini ticker -d
Lets create a simple table that we will replicate from master to read-only’s
mbpro:~/temp kristokaiv$ psql -c "CREATE TABLE users (username text primary key, password text);" write mbpro:~/temp kristokaiv$ psql -c "CREATE TABLE users (username text primary key, password text);" ro1 mbpro:~/temp kristokaiv$ psql -c "CREATE TABLE users (username text primary key, password text);" ro2
And add it to replication
mbpro:~/temp kristokaiv$ londiste.py replica1.ini provider add users mbpro:~/temp kristokaiv$ londiste.py replica1.ini subscriber add users mbpro:~/temp kristokaiv$ londiste.py replica2.ini subscriber add users
After some time the tables should be up to date. Insert a new record in the write database and check if it’s delivered to both read-only db’s.
The functions to insert and select from users table:
CREATE OR REPLACE FUNCTION public.add_user(
in i_username text,
in i_password text,
out status_code text
) AS $$
BEGIN
PERFORM 1 FROM users WHERE username = i_username;
IF NOT FOUND THEN
INSERT INTO users (username, password) VALUES (i_username, i_password);
status_code = 'OK';
ELSE
status_code = 'user exists';
END IF;
RETURN;
END; $$ LANGUAGE plpgsql SECURITY DEFINER;
GRANT EXECUTE ON FUNCTION public.add_user(
in i_username text,
in i_password text,
out status_code text
) TO plproxy;
CREATE OR REPLACE FUNCTION login(
in i_username text,
in i_password text,
out status_code text
) AS $$
BEGIN
SELECT 'OK' FROM users u WHERE username = i_username AND password = i_password INTO status_code;
IF NOT FOUND THEN status_code = 'FAILED'; END IF;
RETURN;
END; $$ LANGUAGE plpgsql SECURITY DEFINER;
GRANT EXECUTE ON FUNCTION login(
in i_username text,
in i_password text,
out status_code text
) TO plproxy;
Just for the comfort of those actually trying to follow these steps, here is how the proxy databases
cluster config:
CREATE OR REPLACE FUNCTION plproxy.get_cluster_partitions (cluster_name text)
RETURNS SETOF text AS $$
BEGIN
IF cluster_name = 'readonly' THEN
RETURN NEXT 'host=127.0.0.1 dbname=ro1';
RETURN NEXT 'host=127.0.0.1 dbname=ro2';
RETURN;
ELSIF cluster_name = 'write' THEN
RETURN NEXT 'host=127.0.0.1 dbname=write';
RETURN;
END IF;
RAISE EXCEPTION 'no such cluster%', cluster_name;
END; $$ LANGUAGE plpgsql SECURITY DEFINER;
CREATE OR REPLACE FUNCTION plproxy.get_cluster_config(
in cluster_name text,
out key text,
out val text)
RETURNS SETOF record AS $$
BEGIN
RETURN;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION plproxy.get_cluster_version(cluster_name text) RETURNS int AS $$
SELECT 1;
$$ LANGUAGE SQL;
The last thing left to do is to create the plproxy function definitions that will redirect the login function calls against read-only databases and add_user calls against write database:
CREATE OR REPLACE FUNCTION public.login(
in i_username text,
in i_password text,
out status_code text
) AS $$
CLUSTER 'readonly'; RUN ON ANY;
$$ LANGUAGE plproxy;
CREATE OR REPLACE FUNCTION public.add_user(
in i_username text,
in i_password text,
out status_code text
) AS $$
CLUSTER 'write';
$$ LANGUAGE plproxy;
This is it, the read-only cluster is ready. Note that even though creating such a read-only cluster seems simple and a quick solution for your performance problems it is not a silver bullet solution. Asynchronous replication often creates more problems than it solves so be careful to replicate only non-timecritical data or guarantee a fallback solution when data is not found (eg. proxy function first checks readonly database and if data is not found looks the data up from write db)
About this entry
You’re currently reading “PostgreSQL cluster: partitioning with plproxy (part II),” an entry on <(-_-)> on PostgreSQL
- Published:
- September 2, 2007 / 6:41 pm
- Category:
- cluster, partitioning, plproxy, postgresql
- Tags:

41 Comments
Jump to comment form | comment rss [?] | trackback uri [?]